OpenClaw and NemoClaw: A Better Way to Consume AI Services Through Token Factory
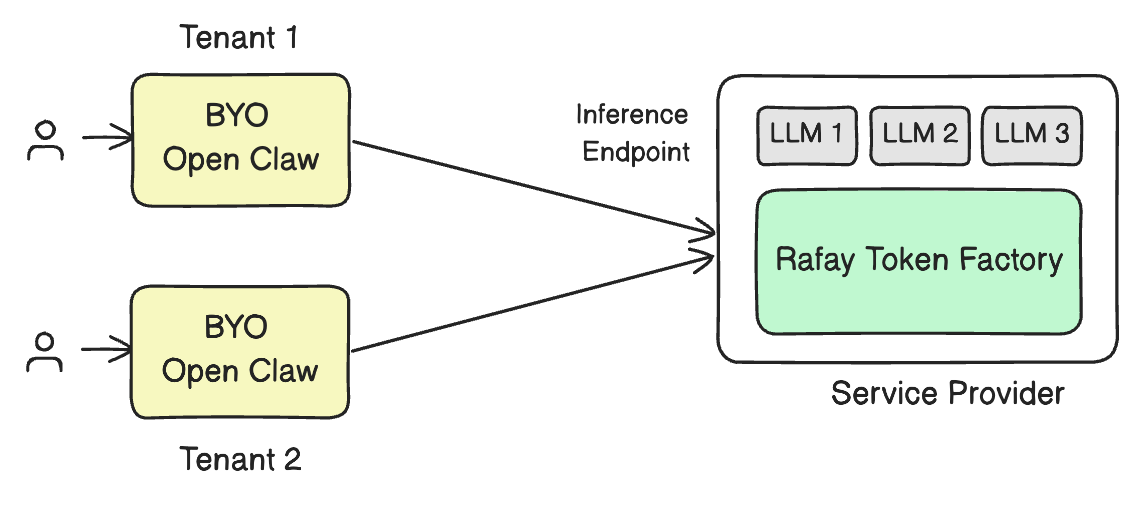
As AI adoption accelerates, most businesses do not actually want to manage GPU clusters, model serving stacks, or low-level infrastructure. What they want is simple, reliable access to powerful models through tools their teams can use immediately. That is exactly the value of combining OpenClaw and NVIDIA NemoClaw with a service provider’s deployment of Rafay Token Factory.
OpenClaw is the user-facing interface where people interact with models and AI assistants. NemoClaw extends that experience with additional security and control for long-running or always-on agents. In both cases, the user experience can remain simple: connect to the provider, use tokens, and start working.
The complexity of GPUs, inference infrastructure, scaling, and capacity planning stays behind the scenes. OpenClaw is the open-source AI agent platform, while NVIDIA describes NemoClaw as an open-source reference stack for running OpenClaw more safely with policy-based privacy and security guardrails.